 架构篇
架构篇
# Mysql 训练营(一)
# mysql默认的连接超时时间
SHOW GLOBAL VARIABLES LIKE 'wait_timeout'
1
# 最大连接数
show variables like 'max_connections'
1
# Mysql sql执行过程
client -> query_cache -> paser (解析器)-> pre processor (预处理器)-> optimizer (优化器)
-> execution plans(执行计划) -> 执行器 (运用执行计划,调用存储引擎api,进行数据交互)
-> 存储引擎
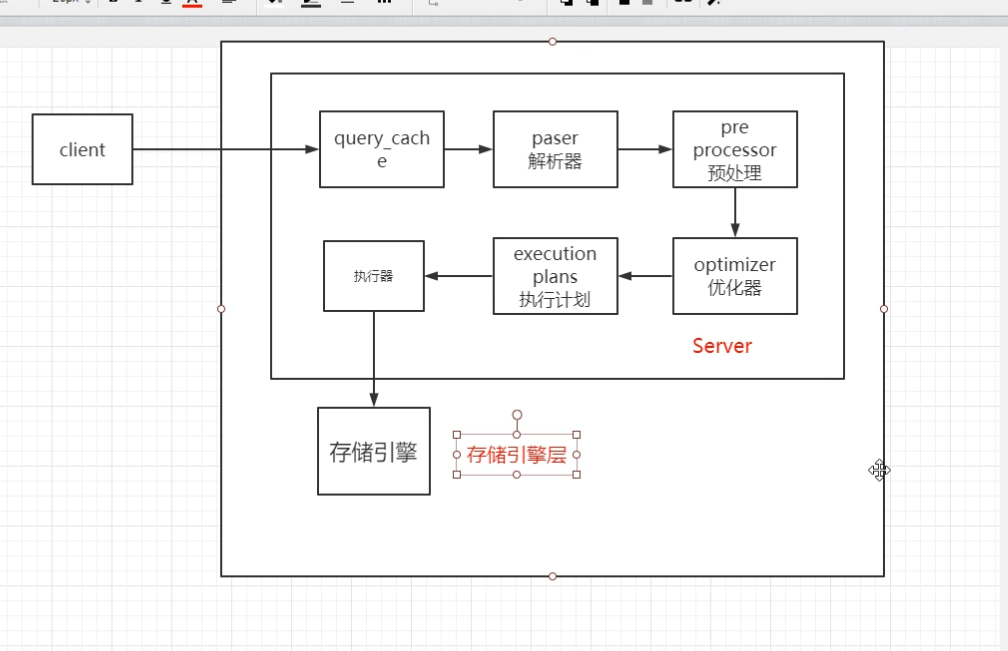
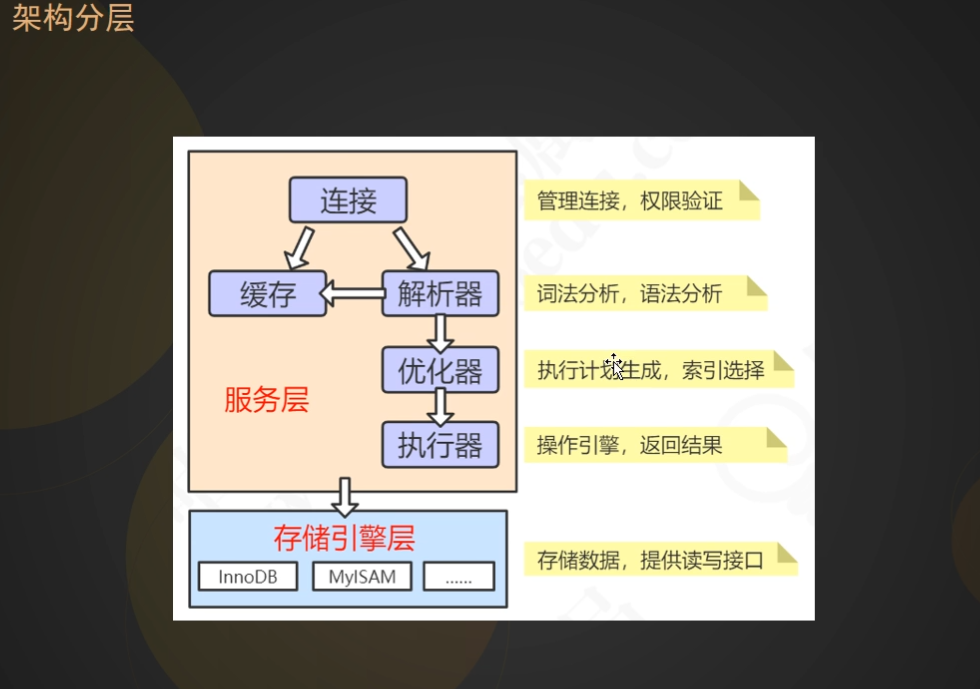
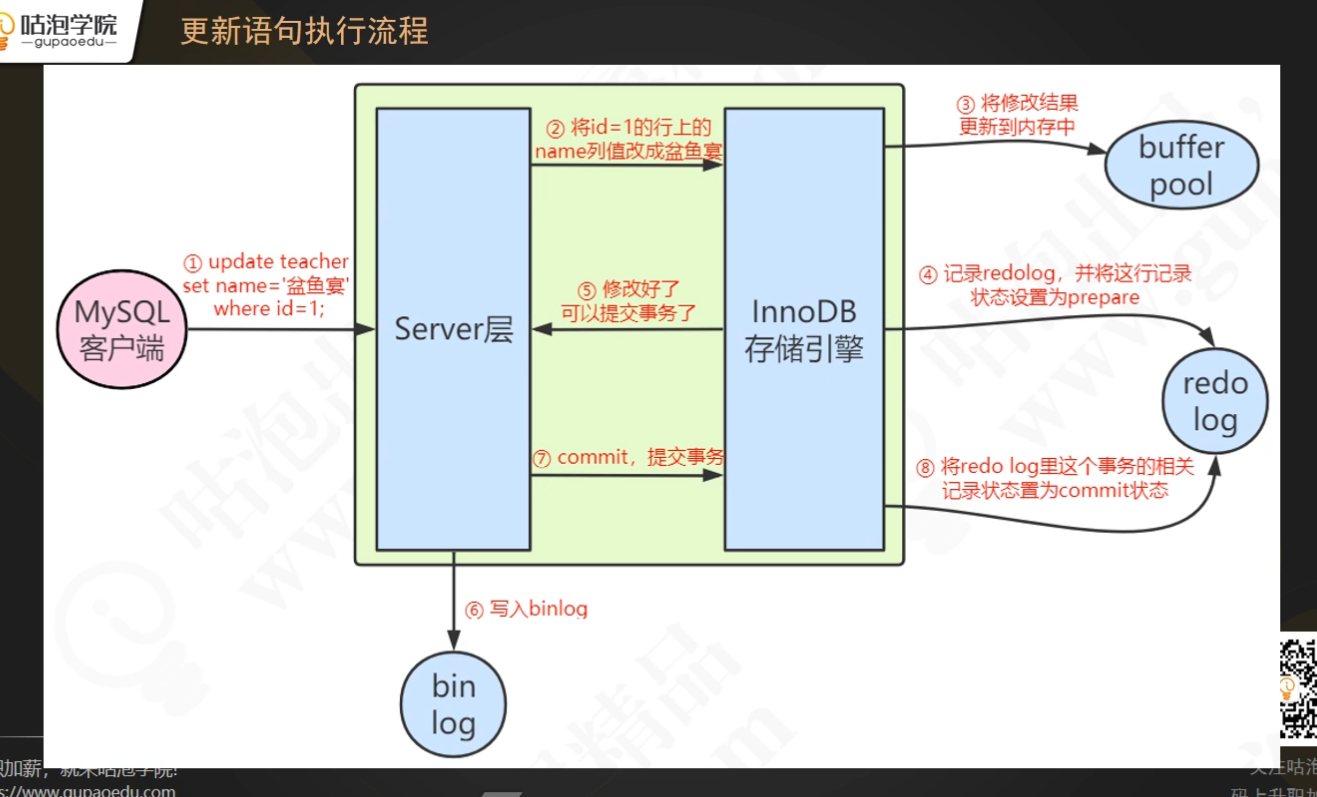
# 一条update(增删改) 在mysql服务端经历了什么?
先从存储引擎中拿到要修改的数据,在执行器中按照sql进行处理数据,处理完成数据之后,在将数据写回到磁盘(这时,就会记录 redo log 和undo log)
# 存储引擎和磁盘 进行交互
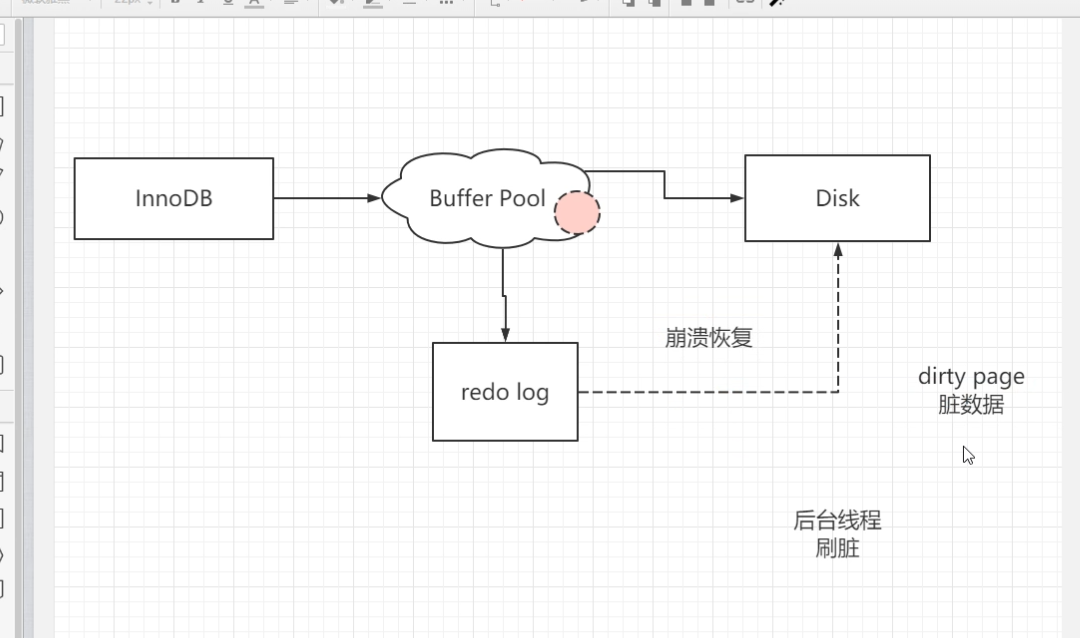
BufferPool 写redo log 的时候,是顺序写入的, 但是写入Disk 中的数据是随机写入的
# undo log
事物回滚需要使用的日志是undo log
# binlog 日志(在server端)
mysql主从数据库的时候,会用到该日志, slave 会订阅binlog日志(记录了 master 中DDL 和 DML语句)
- 记录DDL 和DML 语句
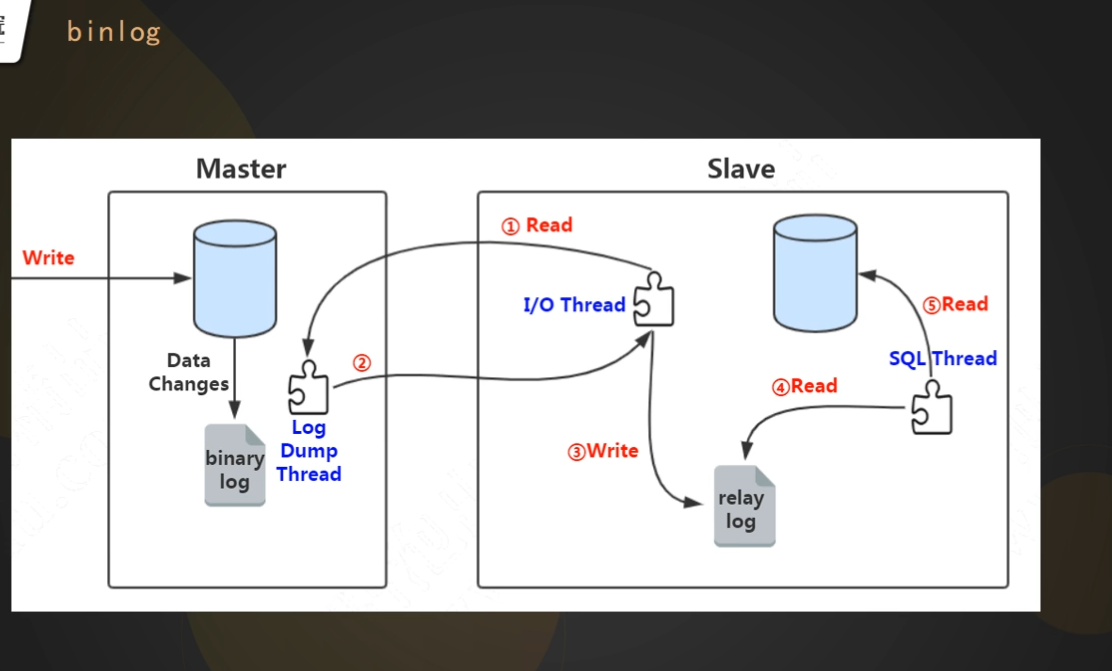
# update 语句整体执行流程
# Exists 和 In 区别
select * from A where id in ( select id from B)
- In 会将 select id from B 中的数据加载到 缓存 中, 如果进行判断时,如果B的数据小, 会大大提高查询效率, 而且 减少内存消耗
select * from A where exists (select 1 from B where B.id = A.id )
- exists 是会执行 A.lenth 次 查询数据库,进行 子查询中数据的比对,如果A越小,那么效率会越高
总结为: In 小表 Exist 大表(B这个时候 要比A 大,这样A就是小表,那么A.lenth就小,那么查询效率就高)
编辑 (opens new window)
上次更新: 2022/05/01, 19:42:49